 An official website of the United States government
An official website of the United States governmentPilot Studies: Common Uses and Misuses
Although pilot studies are a critical step in the process of intervention development and testing, several misconceptions exist on their true uses and misuses. NCCIH has developed a Framework for Developing and Testing Mind and Body Interventions that includes brief information on pilot studies. Here we offer additional guidance specifically on the do’s and don’ts of pilot work.
A pilot study is defined as “A small-scale test of the methods and procedures to be used on a larger scale” (Porta, Dictionary of Epidemiology, 5th edition, 2008). The goal of pilot work is not to test hypotheses about the effects of an intervention, but rather, to assess the feasibility/acceptability of an approach to be used in a larger scale study. Thus, in a pilot study you are not answering the question “Does this intervention work?” Instead you are gathering information to help you answer “Can I do this?”
Uses of Pilot Studies
There are many aspects of feasibility and acceptability to examine to address the “Can I do this?” question. Here are some examples:
| Feasibility Questions | Feasibility Measures |
| Can I recruit my target population? | Number screened per month; number enrolled per month; average time delay from screening to enrollment; average time to enroll enough participants to form classes (group-based interventions) |
| Can I randomize my target population? | Proportion of eligible screens who enroll; proportion of enrolled who attend at least one session |
| Can I keep participants in the study? | Treatment-specific retention rates for study measures; reasons for dropouts |
| Will participants do what they are asked to do? | Treatment-specific adherence rates to study protocol (in-person session attendance, homework, home sessions, etc.); treatment-specific competence measures |
| Can the treatment(s) be delivered per protocol? | Treatment-specific fidelity rates |
| Are the assessments too burdensome? | Proportion of planned assessments that are completed; duration of assessment visits; reasons for dropouts |
| Are the treatment conditions acceptable to participants? | Acceptability ratings; qualitative assessments; reasons for dropouts; treatment-specific preference ratings (pre- and postintervention) |
| Are the treatment conditions credible? | Treatment-specific expectation of benefit ratings |
You may be able to think of other feasibility questions relevant to your specific intervention, population, or design. When designing a pilot study, it is important to set clear quantitative benchmarks for feasibility measures by which you will evaluate successful or unsuccessful feasibility (e.g., a benchmark for assessing adherence rates might be that at least 70 percent of participants in each arm will attend at least 8 of 12 scheduled group sessions). These benchmarks should be relevant to the specific treatment conditions and population under study, and thus will vary from one study to another. While using a randomized design is not always necessary for pilot studies, having a comparison group can provide a more realistic examination of recruitment rates, randomization procedures, implementation of interventions, procedures for maintaining blinded assessments, and the potential to assess for differential dropout rates. Feasibility measures are likely to vary between “open-label” designs, where participants know what they are signing up for, versus a randomized design where they will be assigned to a group.
In addition to providing important feasibility data as described above, pilot studies also provide an opportunity for study teams to develop good clinical practices to enhance the rigor and reproducibility of their research. This includes the development of documentation and informed consent procedures, data collection tools, regulatory reporting procedures, and monitoring procedures.
The goal of pilot studies is not to test hypotheses; thus, no inferential statistics should be proposed. Therefore, it is not necessary to provide power analyses for the proposed sample size of your pilot study. Instead, the proposed pilot study sample size should be based on practical considerations including participant flow, budgetary constraints, and the number of participants needed to reasonably evaluate feasibility goals.
This testing of the methods and procedures to be used in a larger scale study is the critical groundwork we wish to support in PAR-14-182, to pave the way for the larger scale efficacy trial. As part of this process, investigators may also spend time refining their intervention through iterative development and then test the feasibility of their final approach.
Misuses of Pilot Studies
Rather than focusing on feasibility and acceptability, too often, proposed pilot studies focus on inappropriate outcomes, such as determining “preliminary efficacy.” The most common misuses of pilot studies include:
- Attempting to assess safety/tolerability of a treatment,
- Seeking to provide a preliminary test of the research hypothesis, and
- Estimating effect sizes for power calculations of the larger scale study.
Why can’t pilot studies be used to assess safety and tolerability?
Investigators often propose to examine “preliminary safety” of an intervention within a pilot study; however, due to the small sample sizes typically involved in pilot work, they cannot provide useful information on safety except for extreme cases where a death occurs or repeated serious adverse events surface. For most interventions proposed by NCCIH investigators, suspected safety concerns are quite minimal/rare and thus, unlikely to be picked up in a small pilot study. If any safety concerns are detected, group-specific rates with 95 percent confidence intervals should be reported for adverse events. However, if no safety concerns are demonstrated in the pilot study, investigators cannot conclude that the intervention is safe.
Why can’t pilot studies provide a “preliminary test” of the research hypothesis?
We routinely see specific aims for feasibility pilot studies that propose to evaluate “preliminary efficacy” of intervention A for condition X. However, there are two primary reasons why pilot studies cannot be used for this purpose. First, at the time a pilot study is conducted, there is a limited state of knowledge about the best methods to implement the intervention in the patient population under study. Therefore, conclusions about whether the intervention “works” are premature because you don’t yet know whether you implemented it correctly. Second, due to the smaller sample sizes used in pilot studies, they are not powered to answer questions about efficacy. Thus, any estimated effect size is uninterpretable—you do not know whether the “preliminary test” has returned a true result, a false positive result, or a false negative result (see Figure 1).
Why can’t pilot studies estimate effect sizes for power calculations of the larger scale study?
Since any effect size estimated from a pilot study is unstable, it does not provide a useful estimation for power calculations. If a very large effect size was observed in a pilot study and it achieves statistical significance, it only proves that the true effect is likely not zero, but the observed magnitude of the effect may be overestimating the true effect. Power calculations for the subsequent trial based on such effect size would indicate a smaller number of participants than actually needed to detect a clinically meaningful effect, ultimately resulting in a negative trial. On the other hand, if the effect size estimated from the pilot study was very small, the subsequent trial might not even be pursued due to assumptions that the intervention does not work. If the subsequent trial was designed, the power calculations would indicate a much larger number of participants than actually needed to detect an effect, which may reduce chances of funding (too expensive), or if funded, would expose an unnecessary number of participants to the intervention arms (see Figure 1).

Figure 1
So what else can you do to provide effect sizes for power calculations?
Because pilot studies provide unstable estimates of effect size, the recommended approach is to base sample size calculations for efficacy studies on estimates of a clinically meaningful difference as illustrated in Figure 2. Investigators can estimate clincally meaningful differences by consideration of what effect size would be necessary to change clinical behaviors and/or guideline recommendations. In this process it might be beneficial to convene stakeholder groups to determine what type of difference would be meaningful to patient groups, clinicians, practitioners, and/or policymakers. In the determination of a clinically meaningful effect, researchers should also consider the intensity of the intervention and risk of harm vs. the expectation of benefit. Observational data and the effect size seen with a standard treatment can provide useful starting points to help determine clinically meaningful effects. For all of these methods, you should ask the question, “What would make a difference for you?” You might consider using several of these methods and determining a range of effect sizes as a basis for your power calculations.
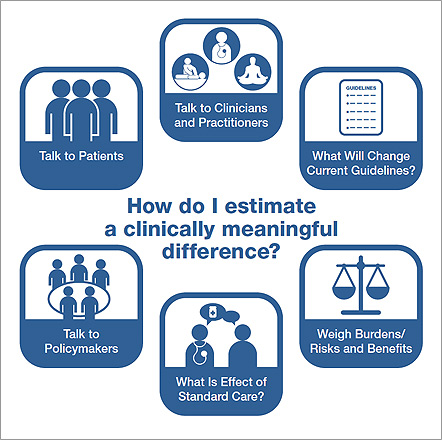
Figure 2
Conclusion
Pilot studies should not be used to test hypotheses about the effects of an intervention. The “Does this work?” question is best left to the full-scale efficacy trial, and the power calculations for that trial are best based on clinically meaningful differences. Instead, pilot studies should assess the feasibility/acceptability of the approach to be used in the larger study, and answer the “Can I do this?” question. You can read more about the other steps involved in developing and testing mind and body interventions on our NCCIH Research Framework page.
Additional Resources:
- Leon AC, Davis LL, Kraemer HC. The role and interpretation of pilot studies in clinical research. Journal of Psychiatric Research. 2011;45(5):626-629.
- Kraemer HC, Mintz J, Noda A, et al. Caution regarding the use of pilot studies to guide power calculations for study proposals. Archives of General Psychiatry. 2006;63(5):484-489.
- Kistin C, Silverstein M. Pilot studies: a critical but potentially misused component of interventional research. JAMA. 2015;314(15):1561-1562.
- Keefe RS, Kraemer HC, Epstein RS, et al. Defining a clinically meaningful effect for the design and interpretation of randomized controlled trials. Innovations in Clinical Neuroscience. 2013;10(5-6 Suppl A):4S-19S.